During [training](How LLMs Work), when performing the "how good was our guess" adjustment, the system doesn't give the same weight to all the words in the sequence:
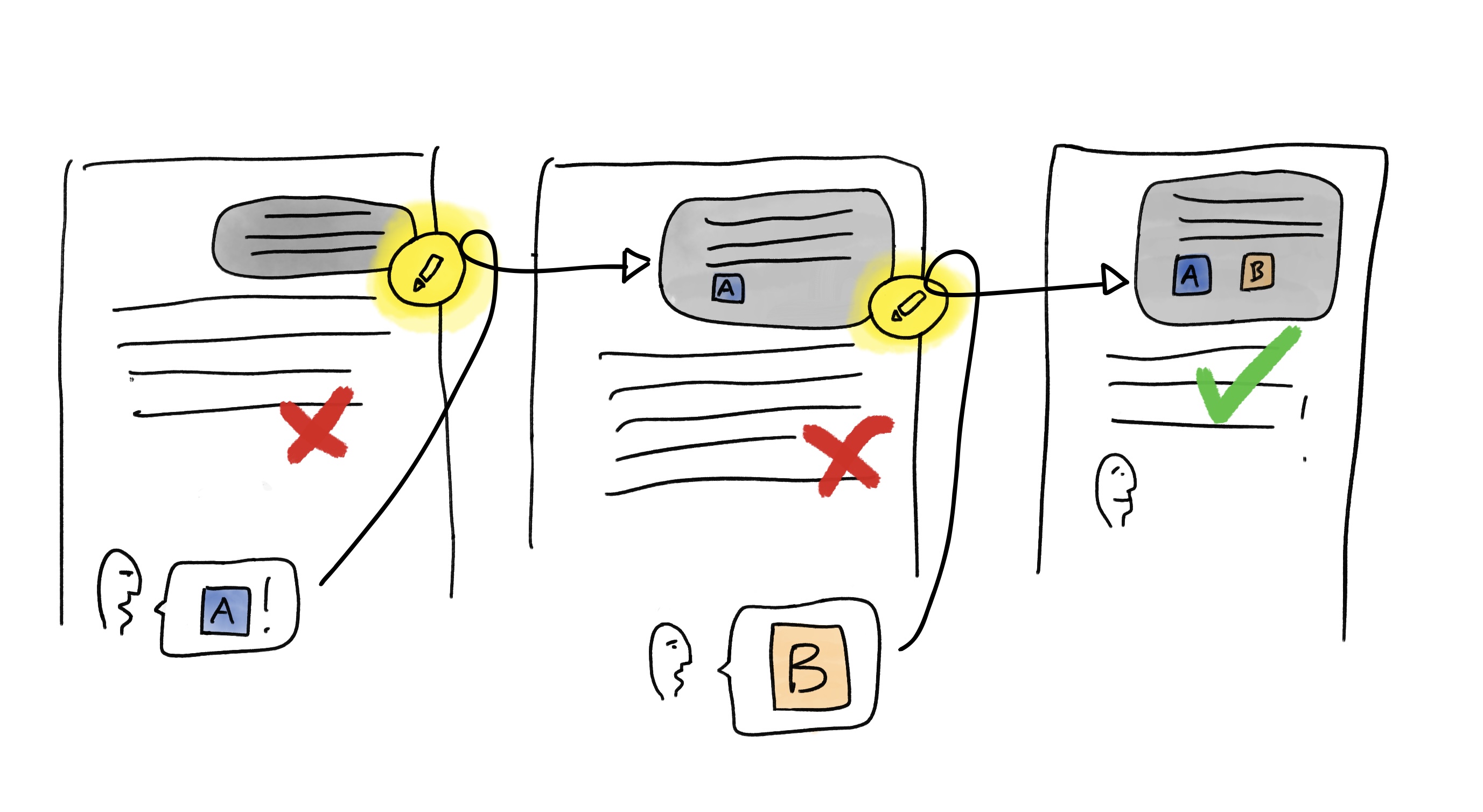
It gives higher importance to the most recent words:
What that means, in practical terms, is that the longer your conversation, the less influence the earlier content has.
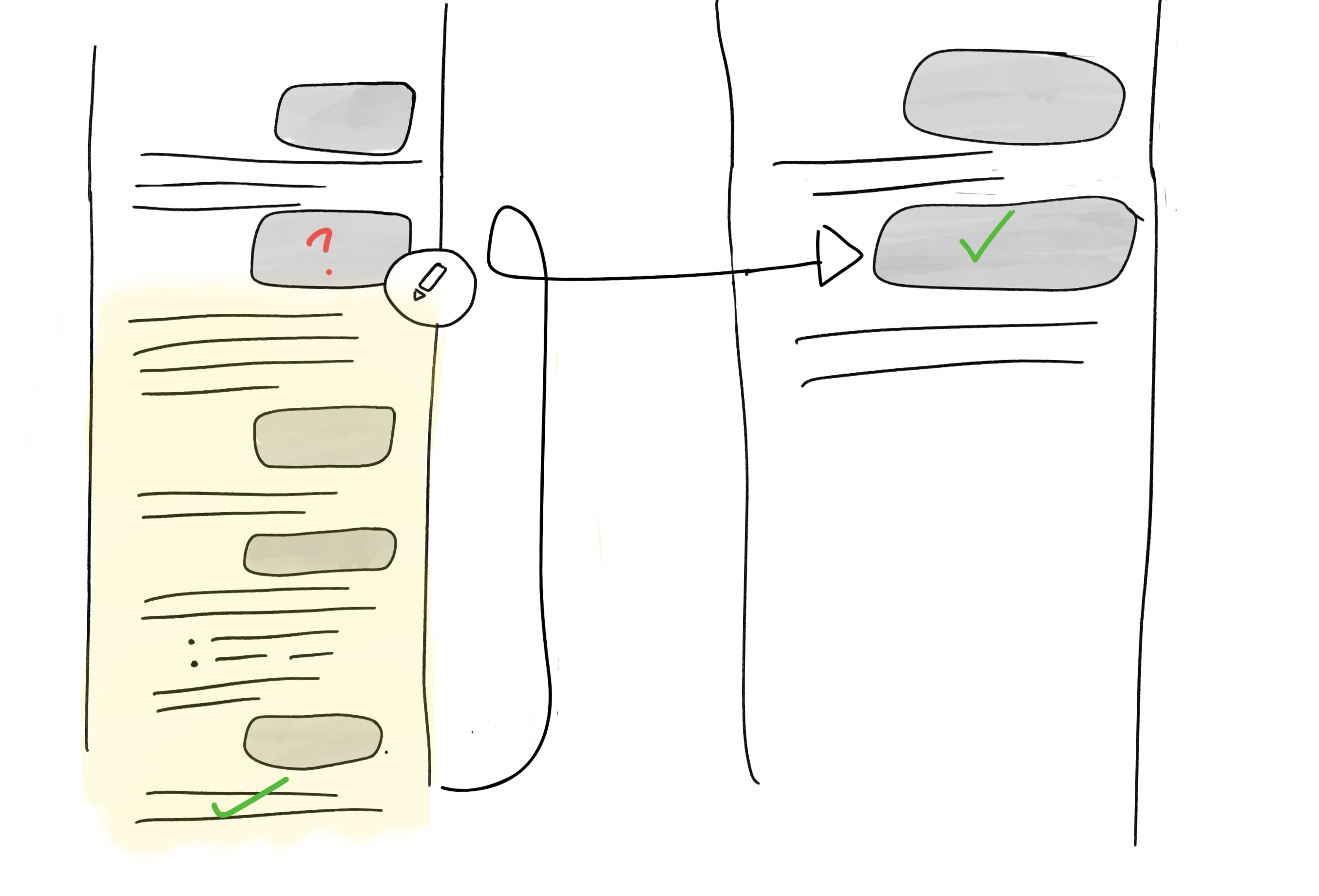
To guess the next word, the LLM primarily focuses on the most recent words. Most model training also add extra weight to the beginning of the conversations, to try to preserve your initial intent or instructions. What gets ignored is actually the middle of a long conversation:
Combatting Recency Bias
If you have a set of constraints that the AI has to operate under, phrase them somewhere as a brief list. Periodically, repeat the list of instructions in your message:
Please rewrite the next section of my resume, keeping in mind:
• Each bullet point must fit on a single line
• Each bullet point must begin with an action verb
• Where possible, quantify the impact to the business
This applies equally to important context—restating your goals every once in a while will help keep the AI on track.
When working with LLMs, I often end up on “side quests”—back-and-forths as I try to figure something out with the AI’s help, or how to phrase something in a way the AI “understands”. This risks distracting the AI with the details of the side conversation, rather than the main substance. Here’s a simple technique to prevent the AI from getting distracted: when you get a response that you don’t like, instead of having an extended dialogue to clarify it**, go back end edit the previous message**, adding clarifications or caveats. If the AI still makes a mistake, add that as an additional condition to your original message.
Alternately, if you do end up on a tangent that yields an interesting insight, scroll back to the point in the conversation where you wish you’d had that insight, and restart your conversation from there—edit the first side-tracking message to continue the conversation with your newfound knowledge.
Many tools like ChatGPT allow you to personalize your assistant by adding a set of instructions that get applied to every conversation.
If you have certain conventions, rules, or standards that you always want your AI to follow, list them here.
There's no guarantee the LLM will follow them, especially once the the conversations get long. Occasionally, the AI will need to be reminded about a particular rule. To make this easier, I create a easy-to-type name for each rule, so I can just tell the AI exactly what rule it’s failed to follow.
Example:
## NoSyntheticData
**Definition**: If you encounter a problem when working with data, NEVER fall back to some fake or simplified data. You can do this in a test in order to debug the issue, but NEVER use fake data in non-test code.
[Examples of violations]
If I catch the AI oversimplifying the problem by using a contrived example, I can simply reply “NoSyntheticData” and it will know exactly what it did wrong and make the appropriate correction. (You can also combine this with the “Go Back in Time” technique, and simply append it as a reminder (“don’t forget: NoSyntheticData”) to your previous request that generated the bad behavior.
This works because LLMs have been optimized for “Needle-in-a-Haystack” use cases—retrieving relevant facts from earlier content. (This optimization is to make something called “RAG” work well. Future post to come.) It might not proactively remember the rule on its own, but if you remind it, it can retrieve and re-state it to bring it to the front of its mind, so to speak.