How LLMs Work
How ChatGPT and other AI chatbots work.
ChatGPT, Claude, Grok, and other chatbots are powered by Large Language Models (LLMs). They are trained on [huge volumes of text](Training Data), primarily scraped from the internet.
All LLMs Do is Guess the Next Word, Over and Over
What follows is a extreme simplification of a complex and evolving science. Don't take it too literally. ¯_(ツ)/¯_
Large Language Models (LLMs) are essentially sequence generators—or, put another way, next-word1 guessers. They take a sequence of text (your prompt and whatever context you give it), and based on how often it’s seen that sequence in its training data, its job is to predict what the best next word will be:
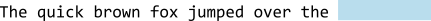
The models are trained on vast amounts of text—sequences of words. Billions of articles, webpages, books, code, documentation, blogs, and now, huge datasets of human conversations with LLMs. The training starts with taking a certain length of text, and hiding the last word. The training program takes its best guess at what the hidden word is, based on all the other times it's seen the prior sequence:

It then judges how far off its guess was from the actual target word, and (hand wavey math 👋🧙♂️) adjusts the probability, either up or down, whether next time, given a similar sequence, it should or should not use the word it guessed.
Then it adds the guessed word to the sequence, slides forward, and does the whole thing again, including the new word:

Training a LLM from scratch means doing this calculation many trillions of times.
(For coding models, it's a little more involved, and involves guessing the word based on both the words before and the words after the target.)
When a LLM responds to you, it evaluates all those probabilities for the input sequence, which includes the entire conversation thus far, including the current response being generated, and picking the most likely next word. Then, sticking that word at the end, it does the probability calculation again. And again. This is why you get your responses in a stream, one word at a time.
All of this in service of getting their next-word guesses as close as possible to what they’ve seen in their training data. A 100% accurate LLM, in theory, would exactly reproduce the most likely sequence from its training data.
Why AI Forgets
Going back to training, however, when performing the "how good was our guess" adjustment, it doesn't give the same weight to all the words in the sequence:
It gives higher importance to the most recent words:

What that means, in practical terms, is that the longer your conversation, the less influence the earlier content has.
see: RecencyBias